はじめに
アソビュー! Advent Calendar 2023の4日目(B面)です。 アソビューでバックエンドエンジニアをしている長友です。
アソビューでは新規開発プロジェクトで用いるデータベースとしてCloud Spannerを導入しました!
Cloud Spannerはフルマネージド型の分散リレーショナルデータベースで高可用性と強力な一貫性を併せ持っています。
ただし、MySQLやPostgreSQLなどの他のDBMSそのままの使い方では上手くいかないことや、パフォーマンスが出ない側面もあります。
弊社としては初の導入となり全員がSpanner未経験の中、その特徴などを少しずつ理解し1年間Spannerと戦ってきました。
そこで今回はこの1年間のSpannerを用いた設計や開発において、Spannerゆえに苦労したこと、今後も気をつけたいことなどを数点紹介していきたいと思います。
開発環境
Cloud Spannerをデータベースとして扱うバックエンドのアプリケーション構成は下記のようになっています。
アプリケーション
- Spring Boot(Java)
設計思想
- DDDとCQRS*1を採用
データベース周りの依存関係
苦労したこと・気をつけたいこと
1. インターリーブを前提としたテーブル設計をする必要があること
Cloud Spannerにおけるテーブル設計で最も意識する必要があったのはインターリーブでした。
詳細な説明は公式ドキュメントに譲りますが、
簡単に言うとテーブル間に親子関係を持たせることによって、その関係にあるテーブルのデータが物理的に同じ場所に格納されるというものです。
利用する対象は従来外部キーでリレーションを持っていた1対多の関係となるようなデータになるかと思います。
このインターリーブは「した方が結合時のパフォーマンスが出る」というより、「できるだけしないとパフォーマンスが辛くなる可能性が高い」と認識しておいた方が良さそうだと実感を伴ってきたのは、実践的なデータを大量投入できる機構が整って諸々の検証ができるようになってからでした。
特に他のDBMSのようにインターリーブではなく外部キーを利用した結合を行うとデータ量によってはパフォーマンスが大幅に劣化してしまいます。
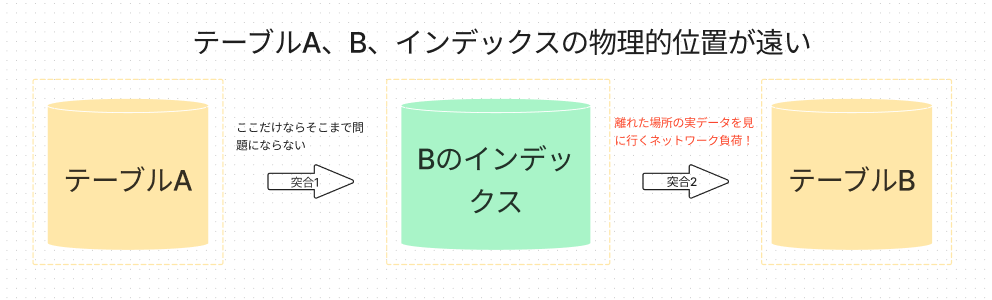
厳密ではないですが、簡単な図で表すと以下のようになると思います。
例えば、
テーブルA
結合で用いられるBのインデックス
テーブルB
の三者が存在しインターリーブを活用していない場合以下のような流れになりますが、
突合1: テーブルAとBのインデックス突合
突合2: 突合2の結果を元にテーブルBの実データを見に行き欲しいデータを取得
この時、特に突合2で生じる離れた場所間のデータ転送のコストが非常に大きくなる可能性があります。
このような特徴が数字として顕著に現れるまでは「インターリーブの階層をいきなり深くしすぎない方が良いのでは?」といった考え方や「外部キーで一旦様子を見てみよう」といった考え方もあり、最終的に「こうした方が良さそう」と全員が同じ方向を向いて設計ができるようになるまでは時間を要しました。
このようなこともあるため、他のDBMSで行う設計や実装をSpannerに適用した時の相性や、公式などから推奨されている設計でどの程度パフォーマンスが変わるのかなど、できるだけ早い段階で様々な検証を重ねる必要があると痛感しました。
また、インターリーブは最大7階層までとなっているので、今後の拡張を考慮すると初期段階では4階層程度までに留めるのがベターと言えるかと思いますが、親に対して登録される子テーブルのレコード量との兼ね合いを考慮し、どのテーブルからインターリーブするか、しないかは今後も都度慎重に判断していく必要があると感じました。
2. 読み取り / 書き込みトランザクションにおいて非常に強力なロックを行うこと
Spannerのトランザクションには「読み取り / 書き込みトランザクション」と「読み取り専用トランザクション」があります。(公式ドキュメント)
この内、データの登録・更新・削除については「読み取り / 書き込みトランザクション」を用いますが、
このトランザクションでselectをすると問答無用で共有ロックを掛けます*3。
これによって一般的なDBMSで生じ得る数々のAnomalyを考えなくて済むようになりますが、不用意なselectは他のトランザクションのwaitやabortを招く可能性があるため、selectするデータの範囲は慎重に考える必要があります。*4
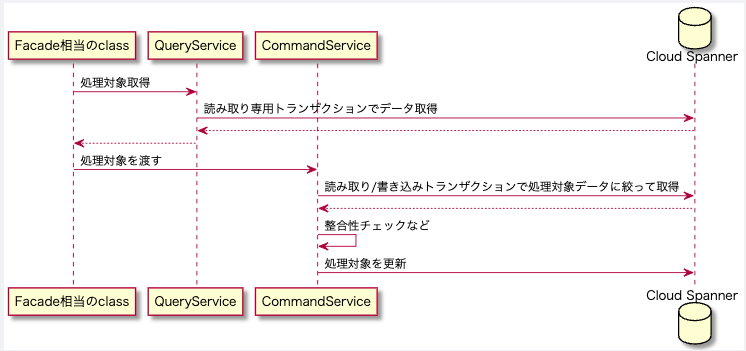
ただし、実際のプロジェクトでは広い範囲をselectした結果から登録・更新対象を判定する必要に迫られる場面もありました。
こういったケースでは読み取り専用トランザクションで一旦処理対象を抽出し、その結果を読み取り / 書き込みトランザクションで再度データ整合性を確認した上で更新するといった手法を取りました。これにより広い範囲への共有ロックは避けることができます。
ただし、このパターンでは読み書き / 書き込みトランザクションでの処理時には更新できない状態になっている可能性があるため、その点も考慮した上で共有ロックを掛けたいケースかそうでないケースかあらかじめ考えて実装方針を決める必要があります。
3. トランザクションにおけるミューテーション数制限
Spannerでは登録・更新・削除などのデータベースに対する変更を表す操作を「ミューテーション」と表現しますが、
1トランザクションにおけるミューテーション数には現状40000という上限があります。
ミューテーション数は単に処理されるレコードの数ではなく操作されるカラムの数や関与するインデックスの数も加算されるため、登録・更新の場合は少なく見積もると1トランザクションあたり数千から1万程度のレコード量が操作可能ということになります*5。
今回のプロジェクトでは一度に数万単位のデータセットの生成が必要な場面があり、このミューテーション数制限によりトランザクションを分割せざるを得ず課題となりました。
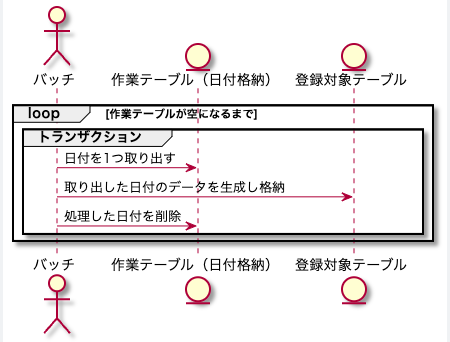
これに対応した実装は以下のような手順となります。
1.生成対象のデータをあらかじめ1トランザクションで処理できる粒度に論理分割しその粒度を作業テーブルに保存
例えば最終的に1月分の在庫データを格納したい場合、それらを日毎や日時のような分割して問題ない粒度に論理分割し、日付や日時の値を作業テーブルに保存します。
2.トランザクションでは1の粒度で登録・更新処理を行い、同時に作業完了した粒度を作業テーブルから削除する
これによって、もし個別のトランザクションが失敗してロールバックされても個別にやり直すことができます。
大量データを扱う際は使われる手法かと思いますが、Spannerを利用する際はこのような処理を組む頻度が上がるのではないでしょうか。
おわりに
今回は新規開発プロジェクトでCloud Spannerを導入して設計・開発した際に苦労したこと・今後も気をつけたいことを数点紹介してみました。
他の事例で言及されているものも多く、「Cloud Spannerあるある」ではないかと思いますが、実際その壁に当たって対応に頭を悩ませたことは非常に良い経験となりました。
Spannerとの戦いは今後も続きます。今回紹介しきれなかったこと、今後新しく得る知見など、他メンバーと共に第二弾、第三弾と取り上げて行きたいと思います!
アソビューでは一緒に働くメンバーを募集しています!
Cloud Spannerに興味のある方、大規模トラフィックやパフォーマンスに向き合ってみたい方なども大歓迎です!
カジュアル面談もやっておりますので、お気軽にエントリーください!
www.asoview.com
*1:CQRSについてはこちらが参考になるかと思います。 CQRS パターン - AWS の規範的ガイダンス
*2:doma2では一部Spannerの構文や型が使えないですが、必要に迫られた際に別の方法も検討したいと考えています
*3:共有ロックについてはこちらを参考にしてください。
Cloud Spanner におけるトランザクションのロックについて | Google Cloud 公式ブログ
*4:回避されるAnomalyについてはこちらの記事が非常に参考になります。 Cloud Spanner を使って様々な Anomaly に立ち向かう | by Yuki Furuyama | google-cloud-jp | Medium
*5:ミューテーションの数え方についてはこちらの記事なども参考にしました。 SpannerにおけるMutationの数え方 #Go - Qiita