アソビュー! Advent Calendar 2022、最後の記事になります。
めりくり〜
アソビューCTOの江部サンタです。 もう今年も年末ですね。一年早すぎやしませんか。
ことしもアソビューでは様々なチャレンジをしてきましたが、その中でプロダクトとしても会社としても一段成長できた象徴的な取り組みとして、昨年から今年5月にかけて実施した可用性向上プロジェクトがありました。
昨年のブログの中で、可用性向上に取り組む、という紹介をしたのですが、今日はその後の結果をご報告できればと思います。 多発する高付加による障害をどのように克服したのか、もし同じような悩みをお持ちの方がいらっしゃれば何かの参考にしてもらえると嬉しいです。
可用性向上プロジェクト発足の背景
弊社ではコロナ以降も毎年高い成長率を維持しており、ありがたいことに多くのお客様にご利用いただいております。 また様々な事業者様からの引き合いもいただき、取り扱う商品も多様化してきています。
2021年には鳥獣戯画展のチケットの取り扱いをするなど、特別展やイベントなども取り扱うようになってきました。 また、コロナ以降、各レジャー施設においても時間あたりの人数制限等が必要になったため、多くの施設で、従来のオープンチケットにかわって日時指定チケットを販売するようになりました。
結果として、枠の限られた商品をめぐってユーザーが集中し、アクセスのスパイクがおこるようになりました。 以下は2022年5月1日と2021年7月23日の、レジャー施設公式サイト経由でのアクセスボリュームのグラフです。

10:00に瞬間的にアクセスがはねあがっています。 このタイミングでとある有名なレジャー施設の、2日のチケット販売が解禁され、すぐ売り切れます。
季節やその時の商品ラインナップによってスパイクが起こる回数やタイミングは異なります。
2021年の夏の同時間はアクセスカウントが0になっていますが、耐えきれていません。 瞬間的にみえますが、多くのお客様がアクセスしていることもあって影響は大きいです。 また、2021年にはほかにも高負荷状態から復旧できず数時間にわたってシステムが停止する障害が4回ほど発生しており、利用者にご迷惑をおかけすることになり、たくさんのクレームもいただきました。 一刻も早くこの状況を打開するため、事業推進系の施策をすべてとめてでも、開発チーム全体で半年間かけて可用性向上に総力を上げることにしました。
障害の原因
いくつか細かいパターンはあるものの、ほとんどのケースはRDBの過負荷起因の障害でした。 弊社では中央にメインのDBクラスタが鎮座しており、ここに問題が起こると広範囲で障害が発生する構造になっていました。

過負荷の要員としては * アクセススパイク * SQLの性能劣化 があり、この両面からの対策が必要でした。
実施した施策
これらを踏まえ、以下の枠組みで対策することとしました。
発生対策
- アクセス負荷からDBを保護する
- SQLの性能劣化を検知し先手の対策をとる
流出対策
- システムのデプロイ速度を上げ、修正の反映速度をあげることによってリカバリ速度を上げる
- 障害発生の場合でも業務がとまらないフローづくり
それぞれかんたんに紹介します。
アクセス負荷からDBを保護する
アソビューではRDBが単一障害点となるためRDBがダウンすると全体に影響が波及しますので、これの保護が重要です。 よって今回は 1. サーキットブレーカーの設置 と 2. CDNの利用拡大 を行うことにしました。
サーキットブレーカーの設置
アプリケーション間や外部システムなどのアクセスにおいて、アクセス先が高負荷状態で処理ができなくなっていたり、サービスダウン状態にある場合に、クライアントから更にアクセスをかけると、クライアントも引きづられて障害に発展、復旧速度の低下、ユーザービリティの低下などの更なる問題に波及します。 過去の障害でも、DB負荷が高騰 → コネクションが枯渇 → DBアクセスしてるアプリケーションのスレッドが枯渇 → APIクライアントとなるアプリケーションのスレッドが枯渇 → ゲストへのレスポンスが返せずタイムアウト/エラー画面表示、といった連鎖的な状態が発生していました。 これらを抑止するため、Resilience4jを利用し、各API呼び出しにサーキットブレーカーを設置しました。
Resilience4jに関してはこちらを参考にさせていただきました。
Introduction to Resilience4j - Speaker Deck
弊社で利用しているSpringBoot用のライブラリも提供されており、アノテーションベースでハンディに処理を記述できます。
// 実装イメージ @CircuitBreaker(name = "payment-service", fallbackMethod = "fallback") public PaymentListResponse paymentList() { return restTemplate.getForObject("http://payment-service/paymentList, PaymentListResponse.class); }
ポイントとしてはブレーカーが発動したときにどのようにハンドリングするかですが、このタイミングではまずはユーザが次の操作にまよわないようなるべく代替フローに誘導するようにしました。
ここは堀りがいのある領域ですので、また別の機会で取り上げられるかもしれません。
CDNの利用拡大
CDNの利用による負荷対策は非常に一般的だとおもいます。
弊社ではこれまでも静的コンテンツの配信などではCDNを活用していました。
しかし、更新頻度が低くても動的な部分は都度生成処理をおこなっていましたので、これを機に動的なコンテンツでもなるべくCDN配信し、DBへのRead回数をへらす取り組みを行いました。

これを実現するために以下のステップを踏みました。
- CDNキャッシュする対象のURLを洗い出す。
- 対象URLのページのコンテンツを精査し、キャッシュ可能なコンテンツとそうでないコンテンツを洗い出す
- 一つのAPIレスポンスでキャッシュ可能なものとそうでなものが混在している場合は分割し、フロントでUIを構築するよう修正。
- 「CloudFront-Is-XXX」ヘッダーによるPC/SP表示の切り替え処理への対応
- CloudFrontがレスポンスで返すコンテンツを判断することになるので、CloudFront側の判定ロジックとJavaアプリケーションを一致させる必要があり、そのためにアプリケーション側で特定のheaderが含まれている場合には、PC/SP表示をCloudFrontと同様のロジックで切り替えれるようにする
- こちらを参考にしました。 https://blog.putise.com/cloudfront-http-headers-addition-change/
- キャッシュ可能なAPIに対してCloud Frontの設定を適用する
- Invalidation方針を設計する。
- 定期的な呼び出し
- 料金情報など、変更反映の即時性を求められる場合の処理フロー

一つ一つ実装の中身を紐解いて行く必要があるためかなり大変な作業ではありますが、 これによるレスポンススピードの向上とDB負荷の抑制はかなり効果的でした。
SQLの性能劣化を検知し先手の対策をとる
SQLの性能は様々な条件によって劣化する場合があります。オプティマイザが突如これまでとは異なる実行計画を選択したり、データ量の変化によって劣化したりします。 弊社でも昨日までスムーズにうごいていたSQL処理が突如劣化して処理が滞留し障害につながることがありました。 このような事態を事前に回避するため、性能劣化を検知する仕組みと体制を構築しました。
通常、弊社ではEmbedded SREの活動の一貫として、各プロダクトチームが担当プロダクトのSLOをモニタリングしエラーバジェットの状況に応じて適切にタスクを切って対応するフローがあります。
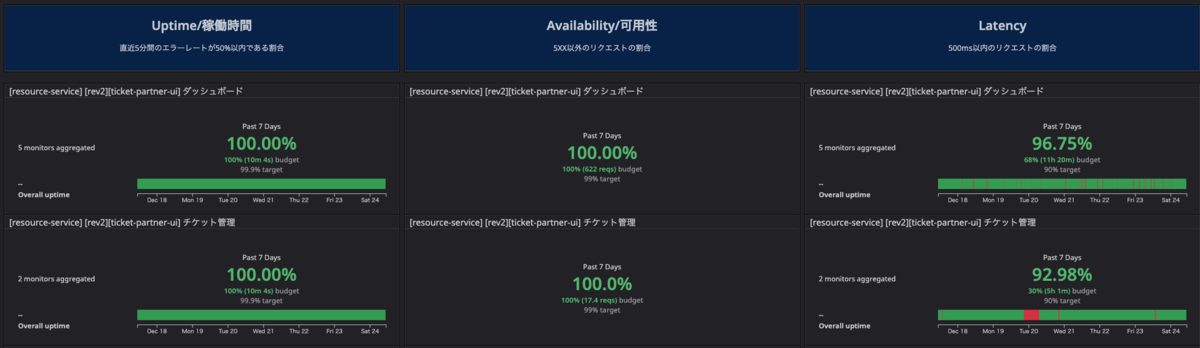
しかしながら、週末や連休や特定の販売イベントの直前で急激なレイテンシーの変化があった場合、スパイクが発生した場合その変化のあおりをもろにうけて命とりになりますので、 この枠組とは別にトレンド変化チェックを人力でおこなっています。
クエリタイムの統計から適切に自動でアラートを上げられるのがベストですが、適切なアラートのチューニングが難しく、 まずは外部の運用会社に協力してもらい、人の目でみて主要なSQL等に対して劣化が発生していないか、激しく変化している場合は即座に対応するなどの対策を実施するようにしました。

泥臭いですが確実に安定性を確保するために重要だとかんがえています。 今後はなるべく自動化できるような対策を模索できればとおもっています。
そのほか弊社のSREの取り組みに関してはここらへんで紹介していますのでぜひ参考にしてみてください。
システムのデプロイ速度を上げ、修正の反映速度をあげることによってリカバリ速度を上げる
もともと対策前にはビルド〜デプロイまで1時間〜1.5時間ほどかかっていましたが、おもにフロント領域のビルド手順の改善により30分程度にまで短縮しました。 1時間といえば月間でいえば0.0014%のダウンタイムに相当しますから、馬鹿にならない対策です。 また、障害対策のみならず弊社のようなリリースサイクルが早い企業にとっても生産性の向上につながります。
障害発生の場合でも業務がとまらないフローづくり
システム障害はあらゆる角度からおこるので、どんなに対策を重ねても可能性は決して0にはなりません。 よって、次同じようなことが起こっても代替フローで対応できる方法を考えておくことは、障害対策と同等以上に重要といえます。
弊社の場合、システム停止によってもっとも影響を大きくうけるのは、レジャー施設への入場業務です。 とくに、連休などで混雑している場合、入場処理がとまれば長蛇の列が発生し、利用者、入場係の方それぞれのストレスはMAXでしょう。 夏の炎天下などなおさらです。 もちろん他にも多くの影響がありますが、顧客にとって損失を生んでしまうのはこの入場オペレーションです。
チケットのユーザストーリーはおおきく「購入」と「着券(利用)」に分けられます。 もともと入場ラッシュを想定し、着券の処理そのものは論理的に分離して構築していましたが、 問題となるのは、購入済みのチケットを呼び出すために踏むステップが正常に動作しなかった場合です。 チケットを呼び出すには
- アソビューにログイン
- 購入チケットの一覧を表示
- 購入チケットの詳細を表示
- QRコードまたはもぎり画面の表示
- 係員がQR読み取りまたはもぎり操作を実施
の4ステップがあり、4〜5は着券プロセスとして分離されているため障害がおこっても波及はないものの、1〜3は着券専用のフローではないため分離されていません。 結果、メインDBに障害が起こった場合、1〜3が利用できず4までたどり着けない。結果としてチケットを買ったのに入場できないという事態が起こりました。 これの対策として、障害発生した場合、4の画面のリンクを各購入者に一斉にメール配信を行い、メールから直接QRまたはもぎり画面を呼び出せる仕組みを構築しました。
幸いにしてまだこの機能を発動する機会はありませんが、障害が発生してしまった場合のコンティンジェンシープランは常に考えておくことが重要だと思います。
まとめ
他にもここでは紹介していない様々な負荷対策、対障害施策などを実施していますが、この可用性向上プロジェクトは、事業成長に対する優先度が高い中で、会社全体として「安全第一」をかかげ、攻めの施策を止めて完全に守りに振り切った象徴的な取り組みであったとおもっています。 これにより、2022年は細かい問題はあれど大きな障害も発生せず、安定的に利用者に価値を届けることができました! もちろん、まだまだ改善の余地はたくさんありますので、これからもユーザに安心安全にご利用いただけるプロダクトをつくって行きたいとおもいます。
最後にお約束です。 アソビューでは常に一緒にプロダクト開発をするエンジニアを求めています。 僕たちは様々な困難を乗り越えながら常にレベルアップしている組織です。 チームとともにエンジニアとして成長したいと考えている皆様のご応募お待ちしております!