こんにちは、アソビューCTOの江部です。
ようやく暑さが少し緩やかになって、夏の終わりを感じるようになった今日このごろ、皆様いかがお過ごしでしょうか。 アソビューは毎年、とくにゴールデンウィークや夏休みが繁忙期になるのですが、今年もなんとか乗り切ることができて安堵しているところです。
今回は、システムを運用する会社であれば避けては通れないシステム障害への備えについて、アソビューの取り組みを紹介しようかと思います。
弊社のサービスは、一般的には予約サイトと認知されていますが、コアとなるシステムにはレジャー施設・イベント向けに提供しているチケット発券および入場管理SaaSがあります。 各レジャー施設の売上とオペレーションを支えるミッションクリティカル度合いの高いシステムになっていますので、いざ問題が発生した場合、重大なケースでは全国の施設の現場で大混乱が起こるなど、ただではすまない事態となります。 そういった涙なしでは語れない様々な苦境をのリ超えて来たわけですが、その経験から障害に対する備えといざというときの対応フローが確立されてきました。 ということで、いざ障害に向き合う際に、あわてず効率的に動けるような取り組みや決め事を、一部ですが簡単に紹介します。 特に、一般的に企業で準備されるインシデント対応フローのフォーマットに表れない部分を取り上げていければとおもっています。 業種や業態などによってとるべき対応が異なることは大いにあるかとおもいますが、誰かの参考になれば幸いです。
障害発生報告と対応開始までの流れをルール化する
第一発見者のアクション
いざ問題が発生したときに、全員が迅速に動けるよう、ルール化し事前に周知しておくようにしましょう。 とくに、障害発生の疑いがあった場合にファーストアクションとしてどうすべきかは、誰でも第一発見者になりうるので、全員ルールを把握しておくことが大事です。 アソビューの場合は、非常にシンプルで
とにかく疑わしかったら24時間365日、Slackのhotlineチャンネルに@channelに報告する
というルールにしています。

重要なポイントとしては、
第一発見者になった場合の報告の心理的ハードルを下げることです。 こういった広範囲に通知のいくような投稿は誰しも躊躇するものです。
- 自分だけの事象だったらどうしよう
- まちがって報告してお騒がせにならないかな・・
などの心配もあるとはおもいますが、
結果的に誤報でも全然OK! おしえてくれてありがとう!
というルールとスタンスを明確にすることが重要です。
障害発生宣言とコミュニケーションチャンネルの開設
つぎに、報告があがってから対応開始するまでの一連の流れです。
- 報告された内容を調査した結果障害であると判断された場合、障害発生を宣言
- 障害対応専用のSlackチャンネルを開設
- 関連する情報を集約し、分散をせぐことにより状況の見通しをよくするため
- 命名規則: #incdent_YYYYMMDD_[障害タイトル]
- Pagerdutyを発火し各領域のキーマン全員に対して通知する。
- 業務時間外に規模の大きい障害が発生し広範囲の対応が必要と想定される場合に発火
- オンラインのブリッジコールを開設する。
- 顧客対応の話題とシステム対応の話題が混合しないよう、システム復旧チームと顧客対応チームを分けて開設する。
- ブリッジ役は両方のチャンネルに参加する。
上記の4ステップはどんな内容かに関わらず自然に動けるよう、とくに繁忙期前にフローの読み合わせを行います。
障害発生時の対応責任者を事前に決めておく
障害が発生した場合、それぞれの領域の責任者およびその代行者、代行順位を決めておくことで、誰が旗を振るべきかを事前に明確にしておきます。 アソビューの場合では以下の領域で、それぞれ代行順位4位までを設定しています。
- 顧客(対ゲスト・・・一般消費者)
- 顧客(対パートナー・・・レジャー事業者)
- システム
- ブリッジング役・・・顧客担当とシステム担当間の橋渡し役
各対応チームのフォーメーションと役割を事前に決めておく
どのようなシステム障害であっても、調査・復旧・根本対応・再発防止・報告の一連のやるべきことはそう大差ありません。 スポーツのフォーメーションのように、ある程度ポジションを決めておいて、いざ発生したときにはポジションに人をアサインしていくことで初動を効率的に行うことができます。 アソビューでは以下のようなフォーメーションを事前に想定しています。
コマンダー
システム担当対応責任者として障害対応の旗振り役を担う。対応方針の決定、担当者の指名、各担当者への作業指示、報告等を担う。通常はCTOまたはそれに次ぐマネジメント上位者が担当。
原因調査担当
発生している現象の原因調査とそのための情報収集を任務とする。障害領域の開発担当が担うケースが多い。
応急処置担当
定めた手順・ルールに則りサービスの再起動、軽微な修正コードのデプロイなどを行い復旧を試みる。SRE+αで対応することが多い
影響範囲担当
ある程度原因が判明したタイミングで、上記以外の人員で影響範囲を確認する
根本対応担当
原因判明後、障害の原因に対する根本的対応を行う
記録担当
発生したイベントや実施した対応をタイムラインで記録したり、ドキュメント上の情報を整理したりする。
上記のポジションは各事象によってコマンダーがタイミングや必要性を判断してアサインします。 場合によっては流動的に変える事もあれば、複数兼務するケースもありえます。 このようにある程度TODOを想定したポジションを想定しておくことで、全員が同じボールを追いかけるような非効率な動きにならないようにすることができます。
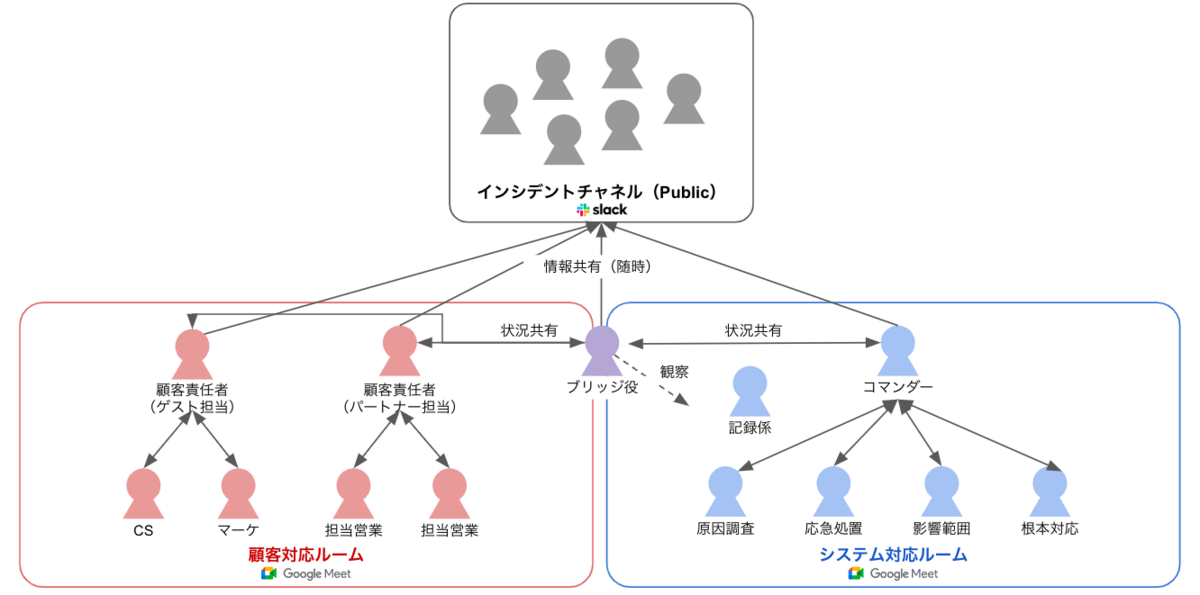
ブリッジング担当者について
顧客対応の担当者(営業メンバーやカスタマーサポートなど)は、顧客からの問い合わせや報告に対応するために、タイムリーに状況を把握しておく必要があります。
一方で、システム担当は目前の障害への対応に注力しているので、細かいレポーティングをすることは難しいことが多いです。
これらをつなぐ役としてブリッジング役を設置し、システム対応および顧客対応両方のオンラインミーティングに入室します。ブリッジング役は、システム対応チームの状況を取りまとめて適宜顧客対応チームに情報共有を行います。
システムチームの会話を理解し適切に翻訳できる知識とコミュニケーションスキルが求められるので、役割を果たせる人員は限られていることが多いです。よって予め想定する人とその代行者を決めておくことが重要です。(アソビューではプロダクトとビジネスの理解の範囲が広いCXOクラスが担います。)
記録用共同編集ドキュメントを早期に用意する
記録担当となる人が、障害対応開始から早期に共同編集ドキュメントを用意し共有します。 このドキュメントに対応メンバーで随時追記していき、誰でも閲覧できるようにします。 弊社ではConfluence上に記録しています。
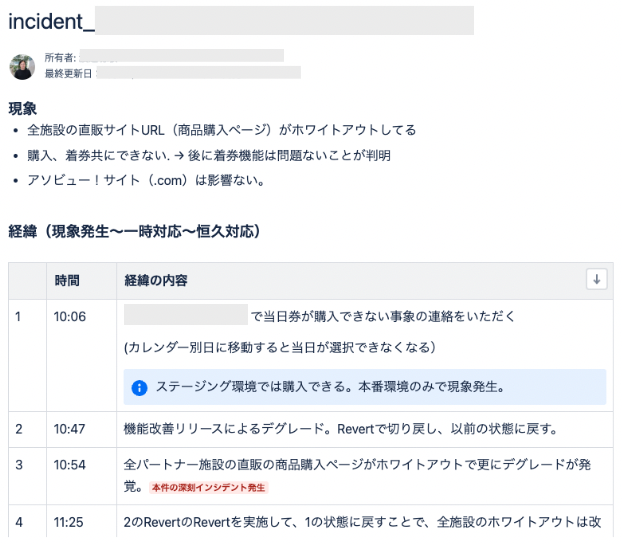
この記録は障害報告書のベースになり、かつポストモーテムを効果的に実施するために必要不可欠な情報となります。 あとでまとめて正確に書き起こすのはかなり大変なので、対応実施の都度きちんと記録を残しておくことが重要です。 報告書と同様のフォーマットで残しておくと便利です。
- 発生事象
- 何が起こったか
- 経緯・復旧作業の対応履歴
- 〇〇時〇〇分: DB再起動、〇〇時〇〇分: 〇〇の修正をデプロイ、〇〇の復旧を確認、など
- 影響範囲
- 顧客軸
- 機能軸
- 時間軸
- 二次被害の有無
- 原因調査記録と考察
- ログやデータのスナップショットなど
- ファクトから導ける仮説とその検証内容
- 最終的な原因
- 再発防止策
その他の取り組み、心構え、気をつけること
障害対応は本当に大きいテーマであり、幅も広ければ奥も深い領域なのでなかなかこのブログのみで整理しきるのは難しいのですが、他にもいろいろ抑えるポイントがありますので思いつく限りを羅列してみます。
- 顧客ファーストで考える。顧客への影響・被害を最小化すること、適時に適切な情報を提供することを第一優先に考える。
- 日頃から障害は起こるものだということを全社員が認識する。アソビューはアクセスの急激な増加によって痛い目をみたことが何度もあるので、引き金になりそうなイベントや予定の情報を必ず共有するようビジデブのみんなにもお願いをし、全員で障害を未然に防ぐ意識をする。
- SLOに基づくSRE活動を着実に実行する。
- 休憩や食事の時間の確保をわすれずとるようにする。(集中してるとわすれがち)
- 当日中に対応しなければならないことはなにか、可能な限り早めに決める。復旧と最低限の再発防止は時間に関わらず直ちにする必要があるが、必要以上に夜おそくまで対応せず休む。報告事項の整理や継続調査など翌日以降もやることは多い。
- システムとしての対応が終わったあとも、顧客への説明や謝罪の対応をしている仲間を認識し、必要な支援を提供する。
- ポストモーテムを実施し組織としての学びにつなげる
- https://tech.asoview.co.jp/entry/2022/12/14/114049#%E3%83%9D%E3%82%B9%E3%83%88%E3%83%A2%E3%83%BC%E3%83%86%E3%83%A0
- 再発防止策を確実に実行する。
- 予防(こうした障害の再発をポジティブに防ぐにはどうしたらいいか)
- 検出(同様の障害を正確に検出するまでの時間を減らすにはどうすべきか)
- 緩和(次回この種の障害が起きたときの深刻度や影響度の%を減らすにはどうしたらいいか)
- 修正(次回障害が検出されたときにどうすればより速く回復できるか)
- 繁忙期前にはインシデント対応フローの読み合わせを部門横断でおこなう。
- Pagerdutyの通知発火テストなど、可能な範囲で訓練を行う。
さいごに
いささかまとまりのない文章になってしまいました。 とにかくいざというときに慌てず効率的に動くために大事なことは、事前に想定された準備と心構えにつきます。 アソビューでは着実に規模の大きな障害は少なくなっており、なかなかこういった対応を実践することはあまりないのですが、今後もよりブラッシュアップしていこうとおもっています。
アソビューでは「生きるに、遊びを。」をミッションに、一緒に働くメンバーを募集しています!ご興味がありましたらお気軽にご応募いただければと思います!